Cómo construir un chatbot con memoria usando Redis, Vertex AI y Docker
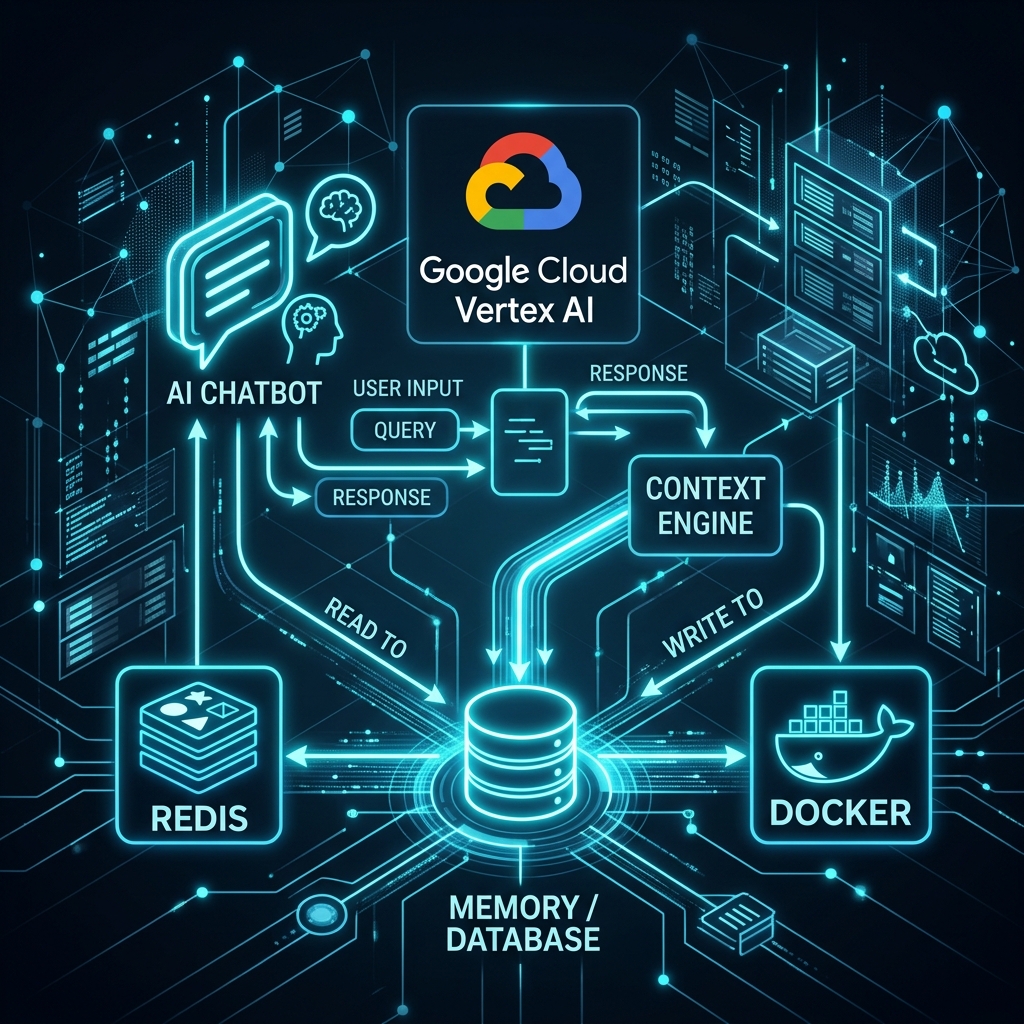
En la era de la IA generativa, un chatbot que olvida lo que dijiste hace dos mensajes no es más que un juguete. Para aplicaciones empresariales, la memoria conversacional es crítica. En este tutorial, exploraremos cómo construir una arquitectura robusta utilizando Redis como capa de persistencia volátil, Vertex AI (Google Cloud) como motor de inteligencia, y Docker para orquestar todo de forma escalable.
La Arquitectura
A diferencia de los ejemplos simples, una arquitectura de producción separa la lógica de negocio de la gestión de estado y el proveedor de IA.
[ Usuario ] <---> [ API Backend (Node/Python) ] <---> [ Vertex AI ]
^
| (Persistencia de Sesión)
v
[ Redis ]
Componentes Clave:
- Vertex AI: Proporciona el modelo (ej. Gemini 1.5 Pro) con latencia baja y seguridad enterprise.
- Redis: Almacena los últimos N mensajes de cada
sessionIdcon un tiempo de vida (TTL) definido. - Docker Compose: Facilita el despliegue de ambos servicios asegurando que el backend siempre pueda alcanzar a Redis por nombre de host.
Estructura del Proyecto
/ai-chatbot
├── src/
│ ├── index.ts # Punto de entrada
│ ├── memory.ts # Lógica de Redis
│ └── vertex.ts # Integración con Google Cloud
├── .env.example
├── Dockerfile
└── docker-compose.yml
Orquestación con Docker
Para asegurar que nuestro entorno de desarrollo sea idéntico al de producción, usamos Docker.
Dockerfile
Usamos una imagen ligera de Node.js para el backend.
FROM node:20-slim
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
RUN npm run build
CMD ["node", "dist/index.js"]
docker-compose.yml
Definimos el servicio de la API y la instancia de Redis.
version: '3.8'
services:
api:
build: .
ports:
- "3000:3000"
environment:
- REDIS_URL=redis://cache:6379
- GOOGLE_APPLICATION_CREDENTIALS=/app/keys/service-account.json
volumes:
- ./keys:/app/keys:ro
depends_on:
- cache
cache:
image: redis:alpine
ports:
- "6379:6379"
Estrategia de Memoria con Redis
No queremos enviar toda la historia de la conversación a Vertex AI, ya que esto incrementaría los costos y superaría el límite de tokens. Nuestra estrategia será:
- Identificar la conversación por
sessionId. - Recuperar los últimos 10 mensajes.
- Actualizar la historia con el nuevo mensaje del usuario y la respuesta de la IA.
// memory.ts
import { createClient } from 'redis';
const client = createClient({ url: process.env.REDIS_URL });
export async function getChatHistory(sessionId: string) {
const history = await client.lRange(`chat:${sessionId}`, 0, 10);
return history.map(m => JSON.parse(m));
}
export async function saveMessage(sessionId: string, message: any) {
await client.rPush(`chat:${sessionId}`, JSON.stringify(message));
await client.expire(`chat:${sessionId}`, 3600); // Expira en 1 hora
}
Integración con Vertex AI
Usamos el SDK oficial de Google Cloud para interactuar con Gemini.
// vertex.ts
import { VertexAI } from '@google-cloud/vertexai';
const vertexAI = new VertexAI({ project: 'your-project-id', location: 'us-central1' });
const model = vertexAI.getGenerativeModel({ model: 'gemini-1.5-flash' });
export async function generateResponse(history: any[], prompt: string) {
const chat = model.startChat({ history });
const result = await chat.sendMessage(prompt);
return result.response.candidates[0].content.parts[0].text;
}
El Endpoint de Chat
Finalmente, unimos todo en un endpoint de nuestra API.
// index.ts
app.post('/chat', async (req, res) => {
const { sessionId, message } = req.body;
// 1. Obtener historia de Redis
const history = await getChatHistory(sessionId);
// 2. Generar respuesta con Vertex AI
const aiResponse = await generateResponse(history, message);
// 3. Guardar en memoria
await saveMessage(sessionId, { role: 'user', parts: [{ text: message }] });
await saveMessage(sessionId, { role: 'model', parts: [{ text: aiResponse }] });
res.json({ response: aiResponse });
});
Mejores Prácticas y Seguridad
- Gestión de Secretos: Nunca incluyas el archivo
.jsonde tu Service Account en la imagen de Docker. Usa volúmenes montados (como se muestra en eldocker-compose) o servicios de Secret Management como Google Secret Manager. - Límites de Redis: Usa
LTRIMpara mantener la lista de mensajes en un tamaño máximo constante y evitar que Redis consuma toda la RAM disponible. - Sanitización de Entrada: Aunque Vertex AI tiene filtros de seguridad integrados, siempre valida y sanitiza el input del usuario para evitar ataques de inyección de prompts maliciosos.
Conclusión
Construir un chatbot con memoria no es solo cuestión de enviar texto a una API. Requiere una estrategia clara de gestión de estado y una infraestructura robusta. Al combinar Redis, Vertex AI y Docker, obtienes un sistema escalable, seguro y, lo más importante, capaz de mantener conversaciones coherentes que aportan valor real al negocio.
¿Listo para llevar tu IA al siguiente nivel? En DataTech H&P ayudamos a empresas a implementar estas arquitecturas de manera eficiente y escalable.